overleaf template galleryLaTeX templates and examples — Recent
Discover LaTeX templates and examples to help with everything from writing a journal article to using a specific LaTeX package.

A gussied-up version of the UA Astro thesis template previously passed down for generations via email

Smallest possible LaTeX document for teaching LaTeX
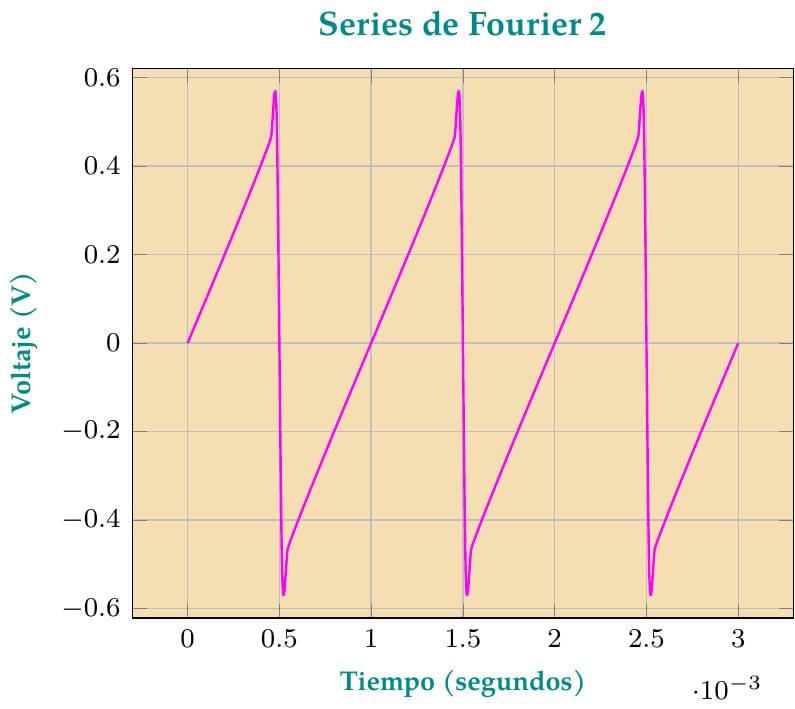
Este gráfico es una mejora, aprovechando el uso de GNUPLOT, de la primera versión que fue publicada por Overleaf. En este caso, la onda de "diente de sierra" es definida según lo indicado en el texto "Mathematical Handbook of Formulas and Tables" de la serie "Schaum's Outlines", de la editorial McGraw Hill, Quinta Edición, página 145. Para mayor precisión, son sumados los 100 primeros términos de la Serie de Fourier, lo cual no afecta grandemente el tiempo de compilación en los servidores de Overleaf.

Model of exercise list

This template is based on https://github.com/uniba-dsg/dsg-templates/tree/master/dsg-seminar-en You can easily get started by defining variables such as the title of your thesis etc. Chose whether you want the title page with one logo or with two logo. Default is one. Images go in the "images" directory. Other resources, e.g. source code files, go in the "resources" directory. Simply start writing by adding sections in the "sections" directory and including these files in "main.tex". Note, that this template is optimized for theses in computer science with Java as main programming language. But feel free to configure listings, e.g. for other languages.
Business card template created by Karol Kozioł. This template supports the following card sizes: ISO 7810 card size (85.60mm–53.98mm) European card size (85mm–55mm) US card size (3.5in–2in) This template was originally published on ShareLaTeX and subsequently moved to Overleaf in October 2019.

This template will be useful for M.Tech students at IIT-Kgp to submit their thesis work.

Proof Portfolio Template for UConn Math 2710W Section 1, Spring 2019. Written by Katie Hall and Erin Rizzie.

LaTex class template for CV/resume. Called Spider CV because of the spider graph, which I did not find already existing on the internet.
\begin
Discover why over 25 million people worldwide trust Overleaf with their work.